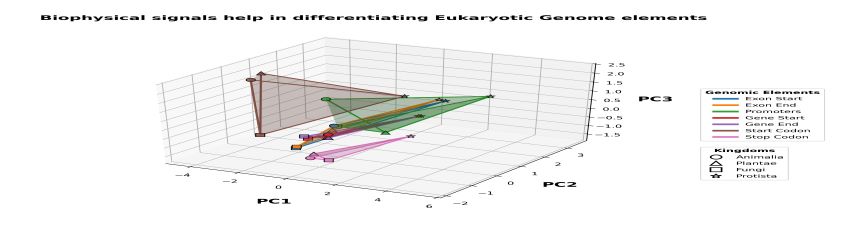
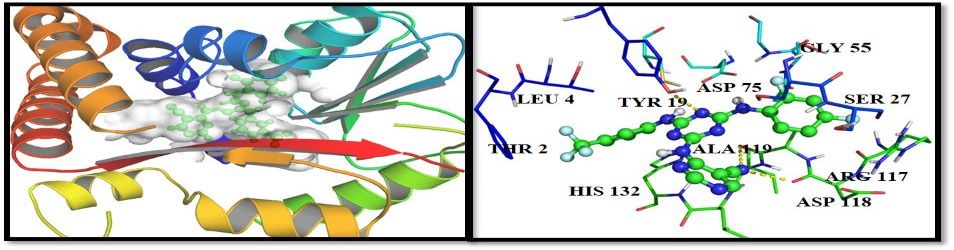
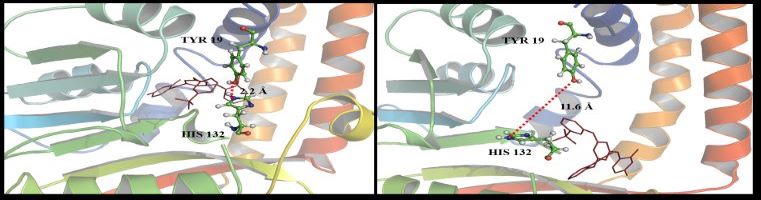
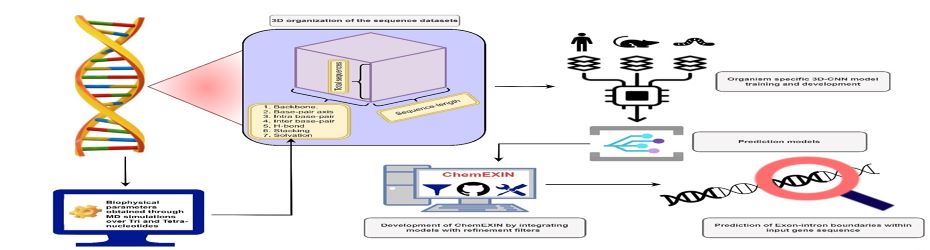
|
|
1. ChemGenome 1.1 (GENE EVALUATOR): ChemGenome is a novel physico-chemical method for identifying protein coding regions on genomic DNA. The software tool accepts DNA sequence in FASTA format and characterizes it as a gene or non-gene based on hydrogen bonding energy, stacking energy and groove potentials for each trinucleotide (codon). Ref.: S. Dutta, P. Singhal, P. Agrawal, R. Tomer, Kritee, E. Khurana, and B. Jayaram, "A Physico-chemical model for analyzing DNA sequences", J. Chem. Inf. Model., 2006, 46, 78-85. http://pubs.acs.org/doi/abs/10.1021/ci050119x |
|
|
2. ChemGenome 2.0 (Gene Predictor): Chemgenome is an ab intio gene prediction software, which finds genes in prokaryotic genomes in all six reading frames. The methodology follows a physico-chemical approach and has been validated on 372 prokaryotic genomes. Ref.: P. Singhal, B. Jayaram, S. B. Dixit and D. L. Beveridge, "Prokaryotic gene finding based on physicochemical characteristics of codons calculated from molecular dynamics simulations",Biophys J., 2008, 94,4173-4183. http://cell.com/biophysj/retrieve/pii/S0006349508700754 | |
|
3. DNA CONVERTER: It accepts DNA sequence and translates it into all possible Amino Acid/Protein Sequences. |
|
4. 4)Oligonucleotide Tm Predictor: It predicts the melting temperature of the given oligonucleotide at a particular salt concentration. The software is based on the hypothesis that hydrogen bonding an dstacking energy dictate the physical and thermal stability of DNA sequences. The user can provide the salt/Na ion concentration or it would take 0.16 M Na ion concentration as the default concentration. The maximum length of the sequence could be 70 bases. Ref.: G. Khandelwal, and B. Jayaram, "A Phenomenological model for predicting melting temperatures of DNA sequences",PLoS One, 2010, 5, e12433. http://plosone.org/article/info:doi/10.1371/journal.pone.0012433 |
|
5. Tm Predictor for Longer Sequences: It predicts the melting temperature of the given DNA at a particular salt concentration. The user can provide the salt/Na ion concentration or it would take 0.16 M Na ion concentration as the default concentration. The minimum length of the sequence should be 70 bases. This tool has been demonstrated on entire genomes in the publications below. Ref.: Garima Khandelwal, Jalaj Gupta and B. Jayaram, "DNA energetics based analyses suggest additional genes in prokaryotes", J. Bio Sc., 2012, 37, 433-444. http://link.springer.com/article/10.1007%2Fs12038-012-9221-7 |
|
6. Gene Predictor(ChemGenome 3.0): ChemGenome 3.0 is a gene prediction tool that takes a whole genome sequence or a part of the genome of a prokaryote or virus as input and predicts genes along with their coressponding protein sequences in all the six reading frames. |
|
|
8.ncRNA Gene Databank: ncRNA Gene Databank is a comprehensive database of genes of non-coding RNA along with their product information. It provides annotation of ncRNA genes from the completely sequenced genomes (2123) from all three domains i.e. Archaea (117), Bacteria (1329) and Eukarya (676). It is distinguishable from other existing databases as: |
|
9. Onco-Regulon: Onco-Regulon is an integrated database of regulatory motifs of cancer genes clubbed with Unique Sequence-Predictor (USP) a software suite that identifies unique sequences for each of these regulatory DNA motifs at the specified position in the genome. Ref.: Akhilesh Mishra, Pradeep Pant, B. Jayaram, "Onco-Plus: an integrated database and computational protocol for discovery of lead molecules targeting unique DNA", J Mol Genet Med, 2018,12:92. DOI: 10.4172/1747-0862-C2-028 | |
10. Pathogen Specific DNA Drug Finder (PSDDF): PSDDF is a computational protocol for identifying unique DNA sequence(s) in the pathogen which is absent in human and related non-pathogenic strains of the microbe. In order to use the unique sequence as drug target, the protocol, in the second step, uses virtual screening against a million compound library to identify candidate small molecules which can bind to these unique DNA targets in the pathogen only. Akhilesh Mishra, Pradeep Pant, Nirotpal Mrinal and B. Jayaram, .A Computational protocol for the discovery of lead molecules targeting DNA unique to pathogens, Methods , 2017,131: 4-9. https://doi.org/10.1016/j.ymeth.2017.07.017 |
|
1. Bhageerath: An automated energy based protein tertiary structure prediction web server. Starting with sequence and secondary structure information, the web server predicts 5 native-like candidate structures for the protein. Ref.: B. Jayaram, K. Bhushan, et al., "Bhageerath: An energy based web enabled computer software suite for limiting the search space of tertiary structures of small globular proteins", Nucl. Acids Res., 2006, 34, 6195-6204. http://nar.oxfordjournals.org/content/34/21/6195.long |
|
2. BhageerathH+:BhageerathH+ software suite implements a hybrid approach by integrating some of the in-house developed methods and seems to deliver reliable structures for the query proteins from their sequence information. The BhageerathH+ software suite is an advanced version of BhageerathH which primarily comprises seven major modules namely secondary structure prediction, conformational sampling, structure scoring for selecting the best conformations, side chain optimization and energy minimization for quality improvement and top five structure selection B Jayaram, Priyanka Dhingra, Avinash Mishra, Rahul Kaushik, Goutam Mukherjee, Ankita Singh and Shashank Shekhar, "Bhageerath-H: A homology ab initio hybrid server for predicting tertiary structures of monomeric soluble proteins", BMC Bioinformatics, 2014, 15(Suppl 16):S7 (8 December 2014). http://biomedcentral.com/1471-2105/15/S16/S7 |
|
3. StrGen (Structure Generation from given dihedrals):StrGen takes the sequence and/or secondary structure information as input and provides the file with Ramachandran values for helix, sheet and loop dihedrals. The dihedrals may be further modified as per the user requirement, to obtain the final structure in PDB format. Ref.: Priyanka Dhingra and B. Jayaram, "A homology/ab initio hybrid algorithm for sampling near-native protein conformations", J Comput.Chem., 2013 34, 1925-36, http://onlinelibrary.wiley.com/doi/10.1002/jcc.23339/abstract |
4. Persistence Length (Filters for Globular Protein Evaluation) Persistence length is the maximum length of the uninterrupted polymer chain persisting in a particular direction. It can be used for flexible polymer chains like proteins, DNA and synthetic polymers. A biophysical filter, which calculates the maximum length of the polypeptide chain in one direction. It is one of the filters employed in the Bhageerath web server for rejection of the non-native like structures from the initial ensemble of trial structures. Ref.: P. Narang, K. Bhushan, S. Bose and B. Jayaram, "A computational pathway for bracketing native-like structures for small alpha helical globular proteins", Phys. Chem. Chem. Phys., 2005, 7, 2364-2375.http://pubs.rsc.org/en/content/articlelanding/2005/CP/b502226f |
5. Radius of Gyration (Filters for Globular Protein Evaluation): Radius of gyration describes the overall spread of the molecule and is defined as the root mean square distance of the collection of atoms from their common centre of gravity. Radius of gyration analysis for a dataset of ~1000 globular proteins from PDB database is performed and the values are plotted against N3/5(N is the no. of Amino Acids). Rg = 0.395*N3/5 + 7.257 . Ref.: P. Narang, K. Bhushan, S. Bose and B. Jayaram, "A computational pathway for bracketing native-like structures for small alpha helical globular proteins", Phys. Chem. Chem. Phys., 2005, 7, 2364-2375." http://pubs.rsc.org/en/content/articlelanding/2005/CP/b502226f |
6. Hydrophobicity Ratio: It comes under the category of biophysical filters, whereby it can help in accepting or rejecting a candidate structure depending on the ratio of accessible surface areas of the hydrophobic and hydrophilic residues. Ref.: P. Narang, K. Bhushan, S. Bose and B. Jayaram, "A computational pathway for bracketing native-like structures for small alpha helical globular proteins", Phys. Chem. Chem. Phys., 2005, 7, 2364-2375. http://pubs.rsc.org/en/content/articlelanding/2005/CP/b502226f |
7. Packing Fraction: It comes under the category of biophysical filters, whereby it can help to evaluate the value of packing fraction for a given protein and to find out whether the value is in acceptable limits for globular protein or not. Ref.: P. Narang, K. Bhushan, S. Bose and B. Jayaram, "A computational pathway for bracketing native-like structures for small alpha helical globular proteins", Phys. Chem. Chem. Phys., 2005, 7, 2364-2375. http://pubs.rsc.org/en/content/articlelanding/2005/CP/b502226f |
|
8.Protein Regulatory Index (ProRegIn): ProRegIn is based on the regularity in the loop dihedral angles of the amino acids. ProRegIn classifies all 20 amino acids in a protein into regular and irregular category for both phi and psi. It can be used to separate improbable structures from native-like probable structures. ProRegIn is currentlyused as one of the filters in Bhageerath methodology. Ref.: L. Thukral, S. R. Shenoy, K. Bhusan and B.Jayaram, "ProRegIn: A regularity index for the selection of native-like tertiary structures of proteins", J. Biosci., 2007, 32, 71-81. http://ncbi.nlm.nih.gov/pubmed/17426381 |
9. Protein structure optimizer: The protein structure optimizer minimizes the energy of the protein structure using a combination of steepest descent and conjugate gradient minimization algorithms. The software uses Cornell et al, 1995 Force Field equation. Ref.: B. Jayaram, K. Bhushan, et al., "Bhageerath: An energy based web enabled computer software suite for limiting the search space of tertiary structures of small globular proteins", Nucl. Acids Res., 2006, 34, 6195-6204. http://nar.oxfordjournals.org/content/34/21/6195.long |
10. Protein Structure Energy Evaluation (ProSEE) Scoring Function for Protein Structure Evaluation calculates intramolecular energy of a protein in component-wise break up. Ref.: P. Narang, K. Bhushan, S. Bose, and B. Jayaram, "Protein structure evaluation using an all-atom energy based empirical scoring function", J. Biomol. Str. Dyn., 2006, 23,385-406. |
11. Superimpose: RMSD stands for Root Mean Square Deviation. It is the square root of the average of the squared distance between each mapped pair of point. It is commonly used to measure degree of similarity in protein structure. RMSD is used in 3D geometry of molecules to measure distance between a given set of points, typically atoms. |
12. Protein Angle Descriptor: This tool calculates the valence angles & dihedral in the main chain of the protein Ref.: P. Narang, K. Bhushan, S. Bose and B. Jayaram, "A computational pathway for bracketing native-like structures for small alpha helical globular proteins", Phys. Chem. Chem. Phys., 2005, 7, 2364-2375. url: http://pubs.rsc.org/en/content/articlelanding/2005/CP/b502226f |
13. Beta Gamma Turn Prediction (BG Pred) : BG Pred web server has the potential to predict beta turn, gamma turn and their types in user input protein sequence using simple statistical approach based on propensities of occurrence of amino acid at a specific position. It also generates motif structure (secondary structure-turn-secondary structure) with predicted turn type within the range of 3.6 Ã… RMSD of the native structure.. |
14. PROTEIN SECONDARY STRUCTURE CHARACTERIZATION (PROSECSC): A tool to predict secondary structure of protein sequence. |
15. pcSM Software: pcSM: Capturing Native Protein Structures with a Physico-Chemical Metric. |
15. Bhageerath-H Strgen: Bhageerath-H Strgen: A Web tool for protein decoy generation. |
16. D2N : D2N: Distance to Native. |
17. Ramchandran Maps to Tertiary Structures of Proteins (RM2TS): We have divided the allowed (Φ, Ψ) space in Ramachandran maps into 27 distinct conformations sufficient to regenerate a structure to within 5 Å from the native, at least for small proteins, thus reducing the structure prediction problem to a specification of an alphanumeric string i.e. amino acid sequence together with one of the 27 conformations preferred by each amino acid residue. Ref.: Debarati DasGupta, Rahul Kaushik, and B. Jayaram "From Ramachandran Maps to Tertiary Structures of Proteins", J. Phys. Chem. B , 2015 . 119 (34), pp 11136 - 11145. DOI: 10.1021/acs.jpcb.5b02999 | 18. Protein Structure Analysis and Validation (ProTSAV): ProTSAV is a meta-server, which has a collection of model quality assessment programs that evaluate the quality of a protein and correctness of the structural model. It predicts a global quality score for submitted input structure. Ref.: Ankita Singh, Rahul Kaushik, Avinash Mishra, Asheesh Shanker and B. Jayaram "ProTSAV: A Protein Tertiary Structure Analysis and Validation Server", BBA - Proteins and Proteomics, 2015. Volume 1864, Issue 1, January 2016, Pages 11 - 19. DOI: 10.1016/j.bbapap.2015.10.004 |
19. Structural Difficulty (SD) Index: Structural Difficulty (SD) index, which is derived from secondary structures, homology and physico-chemical features of protein sequences, reflects the capability of predicting good quality structures with some of the best methodologies available currently. The SD index also helps to assess the plausiblity for developing proteome level structural databases for various organisms. Ref.: Rahul Kaushik, B. Jayaram "Structural difficulty index: A reliable measure for modelability of protein tertiary structures", Protein Engineering Design and Selection, 2016, 29(9), 391-97. doi: 10.1093/protein/gzw025. |
20. Plasmodium Vivax Structural Databank (PvaxDB): PvaxDB databank is a dynamic depository of structural information of Plasmodium vivax which includes sequence and structure based annotations. Ref.: Singh,A., Kaushik,R., Kuntal,H. et al. "PvaxDB: a comprehensive structural repository of Plasmodium vivax proteome". Database, 2018. Vol.2018: doi:10.1093/database/bay021. |
21. Plasmodium Vivax P01 Structural Databank: PvP01DB databank is a dynamic repository of structural information of Plasmodium vivax P01 which includes sequence and structure-based annotations. Ref.: Ankita Singh, Rahul Kaushik, Dheeraj Kumar Chaurasia, Manpreet Singh, B Jayaram "PvP01-DB: computational structural and functional characterization of soluble proteome of PvP01 strain of Plasmodium vivax", Database , Volume 2020, 2020. https://doi.org/10.1093/database/baaa036 |
22. Sequence 2 Function: Seq2Func is an efficient and novel approach to predict protein function from its sequence, which uses the structural-chemical properties of amino acids in place of conventional classifications of the building blocks of proteins. Seq2Func uses NCL+mask BLAST methodology (New Chemical Logic for amino acid properties implemented with maskBLAST) to annotate proteins in terms of Gene Ontology. Ref.: P. Amita; R. Toran; E. Avinash; B. Jayaram; "MASK BLAST WITH A NEW CHEMICAL LOGIC OF AMINO ACIDS FOR IMPROVED PROTEIN FUNCTION PREDICTION: Protein Function Prediction using New Chemical Logic", Proteins: Structure, Function, and Bioinformatics , 2021. https://doi.org/10.1002/prot.26069 &Rahul Kaushik, Ankita Singh and B. Jayaram. "Where informatics lags chemistry leads".Biochemistry, 2018, 55(5): 503-505. DOI: 10.1021/acs.biochem.7b01073 |
23. Sequence 2 Enzymes: Seq2Enz method is a new way of assigning enzyme class to a protein sequence using the structural-chemical properties of amino acids in place of conventional classifications of the building blocks of proteins. Seq2Enz uses NCL+mask BLAST methodology (New Chemical Logic for amino acid properties implemented with maskBLAST) for finding a similar enzyme class by scoring the most frequent ones in the hits. Ref.: Amita Pathak, B.Jayaram, "Seq2Enz: An application of mask BLAST methodology with a new chemical logic of amino acids for improved enzyme function prediction", Biochimica et Biophysica Acta (BBA) - Proteins and Proteomics, 2021. https://doi.org/10.1016/j.bbapap.2021.140721 |
24. Protein Function Prediction Tool (S2F): S2F is a refined and improved amalgamation of several softwares for protein function prediction which are based on different sequence-based approaches. The metaserver provides a single platform to the users to get functional insights of a query protein through different sources like DeepGo, PFP, STRING, Eggnog, InterProScan, Pannzer2 and Seq2Func. This way a user will not miss the opportunity of finding possible functions for a protein sequence. S2F provides the maximum GO terms with high confidence to the users. Ref.: P. Amita; R. Toran; E. Avinash; B. Jayaram; "MASK BLAST WITH A NEW CHEMICAL LOGIC OF AMINO ACIDS FOR IMPROVED PROTEIN FUNCTION PREDICTION: Protein Function Prediction using New Chemical Logic", Proteins: Structure, Function, and Bioinformatics , 2021. https://doi.org/10.1002/prot.26069 |
1. Sanjeevini : Sanjeevini represents a massive ongoing scientific endeavor to provide to the user, a freely accessible state-of-the-art software suite for protein and DNA targeted lead molecule discovery. It builds in several features, including automated detection of active sites, scanning against a million-compound library for identifying hit molecules, all atom-based docking and scoring, and various other utilities to design molecules with desired affinity and specificity against biomolecular targets. Each of the modules is thoroughly validated on a large dataset of protein/DNA drug targets. Ref.: B. Jayaram, N. Latha, T. Jain, P. Sharma, A. Gandhimathi, and V. S. Pandey, "Sanjeevini: A comprehensive Active-Site directed lead design software", Ind. J. Chem., 2006, 45A, 1834-1837. http://niscair.res.in/sciencecommunication/researchjournals/rejour/ijca/ijca2k6/ijca_jan06.asp#p21 &B. Jayaram, Tanya Singh, Goutam Mukherjee, Abhinav Mathur, Shashank Shekhar, and Vandana Shekhar, "Sanjeevini: a freely accessible web-server for target directed lead molecule discovery", BMC Bioinformatics, 2012, 13, S7.http://biomedcentral.com/1471-2105/13/S17/S7 |
2. Dhanvantari : Dhanvantari is a pipeline to incorporate novel scientific methods and highly efficient algorithms along with combining principles of Chemistry and Biology with Information Technology for target directed Drug Designing. The pipeline covers all the aspects from genome through genes, proteins, active site to a final proposed lead like compound. Ref.: Ruchika Bhat, Rahul Kaushik, Ankita Singh, Debarati DasGupta, Abhilash Jayaraj, Anjali Soni, Ashutosh Shandilya, Vandana Shekhar, Shashank Shekhar, B. Jayaram, " A comprehensive automated computer-aided discovery pipeline from genomes to hit molecules" Chemical Engineering Science, 2020. https://doi.org/10.1016/j.ces.2020.115711 |
|
3. Binding Affinity Prediction of Protein-Ligand Server(BAPPL)
: BAPPL server computes the binding free energy of a non-metallo protein-ligand complex using an all-atom energy based empirical scoring function. Ref.: T. Jain, and B. Jayaram, "An all atom energy based computational protocol for predicting binding affinities of protein-ligand complexes", FEBS Letters, 2005, 579, 6659-6666.http://febsletters.org/article/S0014-5793%2805%2901291-3/abstract |
4. Binding Affinity Prediction of Protein-Ligand complex containing Zinc Server (BAPPL-Z) : Binding Affinity Prediction of Protein-Ligand complex containing Zinc [BAPPL-Z] server computes the binding free energy of a zinc containing metalloprotein-ligand complex using an all-atom energy based empirical scoring function. Ref.: T. Jain, and B. Jayaram, "A computational protocol for predicting the binding affinities of zinc containing metalloprotein-ligand complexes", PROTEINS: Struct. Funct. Bioinfo., 2007, 67, 1167-1178. http://onlinelibrary.wiley.com/doi/10.1002/prot.21332/abstract |
5. Improved predicting protein-ligand affinities (BAPPL+) : Bappl+ is an improved methodology for predicting the binding affinities of protein-ligand and metalloprotein-ligand complexes. It computes binding affinity based on the most important energetic contributors such as electrostatics, van der Waals, hydrophobicity and entropy of protein and ligand. For metalloprotein-ligand complexes, it uses the explicitly-derived quantum-optimized charges for various metal ions (Zn, Mn, Mg, Ca and Fe). It uses the Random Forest to derive the final score. Ref.: Anjali Soni, Ruchika Bhat, B. Jayaram, "Improving the binding affinity estimations of protein-ligand complexes using machine-learning facilitated force field method" J Comput Aided Mol Des, 2020. https://doi.org/10.1007/s10822-020-00305-1 |
6. Predict DNA-Drug Interaction strength by Computing ΔTm and Affinity of binding (PreDDICTA) :A hybrid molecular mechanics-statistical mechanics-solvent accessibility-based computational protocol is developed to calculate DNA-ligand binding affinity without any database training and is validated on 50 DNA-ligand complexes. The calculated binding energies yield high correlation coefficients of 0.95 (R2 = 0.90) and 0.96 (R2 = 0.93) in linear plots against experimental binding free energies (DeltaGo) and DeltaTm, respectively. Ref.: S. A. Shaikh and B. Jayaram, "A Swift all-atom energy based computational protocol to predict DNA ligand binding affinity and ΔTm", J. Med. Chem., 2007, 50, 2240-2244. http://pubs.acs.org/doi/abs/10.1021/jm060542c |
7. Automated Server for Protein Ligand Docking (ParDOCK): ParDOCK is an all-atom energy-based Monte Carlo, rigid protein ligand docking, implemented in a fully automated, parallel processing mode which predicts the binding mode of the ligand in receptor target site. The structural input data for the ParDOCK are optimized reference complex i.e. protein bound with a ligand and a candidate ligand to be docked. Ref.: Gupta, A. Gandhimathi, P. Sharma, and B. Jayaram, "ParDOCK: An all atom energy based monte carlo docking protocol for protein-ligand complexes", Protein and Peptide Letters, 2007, 14, 632-646. http://eurekaselect.com/78655/article |
8. Improved version of Automated Server for Protein Ligand Docking (ParDOCK+)
: This is an advanced version of ParDOCK with improved docking algorithm and scoring functions. Manuscript in preparation |
9. Bioactivity of Indian Medicinal Plants (BIMP) :The creation of a comprehensive databank on bioactivities of compounds in Indian medicinal plants involves the systematic collection, curation, and organization of data from various sources. This databank aims to consolidate information on the chemical constituents of medicinal plants, their bioactive properties, and their potential applications in the treatment of various diseases. Manuscript in preparation |
10. Active Site Prediction: Active Site Prediction of Protein server computes the cavities in a given protein. |
11. Automated Active Site Prediction (ASF & AADS): Predicts 10 binding sites in a protein target and docks the uploaded ligand molecule at all 10 sites predicted in an automated mode. Ref.: Tanya Singh, D. Biswas, and B. Jayaram, “AADS - An automated active site identification, docking and scoring protocol for protein targets based on physico-chemical descriptors”, J. Chem. Inf. Modeling, 2011, 51, 2515-2527. http://pubs.acs.org/doi/abs/10.1021/ci200193z |
|
12. Non Redundant Database of Small Molecules(NRDBSM):NRDBSM database is aimed specifically at virtual high throughput screening of small molecules and their further optimization into successful lead-like candidates. It has been developed giving special consideration to physicochemical properties and Lipinski's rule of five, which determine the solubility, permeability and transport characteristics across membranes. Some of these are molecular weight, number of hydrogen bond donors and acceptors, log P and molar refractivity. Fixed precincts for these properties have been employed as filters to assemble the database. Ref.: S. A. Shaikh, T. Jain, G. Sandhu, N. Latha, and B. Jayaram, "From drug target to leads- sketching, A physicochemical pathway for lead molecule design in silico", Curr. Pharma. Des., 2007, 13, 3454-3470. http://eurekaselect.com/66010/article |
13. Lipinski Rule of Five:Lipinski rule of 5 helps in distinguishing between drug like and non-drug like molecules. It predicts high probability of success or failure due to drug likeness for molecules complying with 2 or more of the following rules. Ref.: B. Jayaram, Tanya Singh, Goutam Mukherjee, Abhinav Mathur, Shashank Shekhar, and Vandana Shekhar, "Sanjeevini: a freely accessible web-server for target directed lead molecule discovery", BMC Bioinformatics, 2012, 13, S7. http://biomedcentral.com/1471-2105/13/S17/S7 |
|
14. Molecular Volume Calculator : This tool calculates volume of small molecules (less than 500 atoms). |
15. DNA Sequence to Structure : This tool generates double helical secondary structure of DNA using conformational parameters taken from experimental fiber-diffraction studies.. |
|
16. DNA Ligand Docking: Rigid Docking predicts the binding mode of the ligand in the minor groove of DNA. |
17. Wiener Index Calculator: This tool is useful for calculating Wiener index. This will predict Wiener Index of ligand/molecule. It is an important topological descriptor of a molecule. Wiener index can be further used for deducing various other properties of a ligand/molecule which can be useful in drug designing. |
|
18. Rapid Screening with Physicochemical Descriptors + Machine Learning (RASPD):RASPD+ (RApid Screening with Physicochemical Descriptors + Machine Learning) is a computationally fast protocol for identifying lead-like molecules based on predicted binding free energy against a target protein with a 3D structure and a defined ligand binding pocket. Ref.: Goutam Mukherjee and B. Jayaram, "A Rapid Identification of Hit Molecules for Target Proteins via Physico-Chemical Descriptors", Phys. Chem. Chem. Phys., 2013 15, 9107-16. http://pubs.rsc.org/en/Content/ArticleLanding/2013/CP/C3CP44697 & Stefan Holderbach, Lukas Adam, B Jayaram, Rebecca C. Wade and Goutam Mukherjee, "RASPD+: Fast protein-ligand binding free energy prediction using simplified physicochemical features", Front. Mol. Biosci., 2020. https://doi: 10.3389/fmolb.2020.601065 |
19. Transferrable Partial Atomic Charge Model - up to 4 bonds (TPACM4): This software is used for deriving the partial atomic charges of small molecules for use in protein/DNA-ligand docking and scoring. The main idea of TPACM4 is based on a look up table of template fragments consisting of 4-bond paths around the atom being charged. This method overcomes the limitations of time complexity of assigning the partial atomic charges of a given molecule Ref.: G. Mukherjee, N. Patra, P. Barua and B. Jayaram, "A Fast empirical GAFF compatible partial atomic charge assignment scheme for modeling interactions of small molecules with biomolecular targets (TPACM4)", J. Comput. Chem., 2011, 32, 893-907. http://onlinelibrary.wiley.com/doi/10.1002/jcc.21671/abstract 20. BAITOC: Bioactivity information to organic chemists: Druggable biomolecules are limited but the number of small molecules capable of moderating their activities is huge. Instead of searching for a molecule for a given target, a new approach to finding a target for a known molecule can also be utilized. There are many molecules that are synthesized in laboratories across the globe but are never tested for their bioactivity. Also, cases exist where bioactive compounds are known but their biomolecular targets are unknown. Baitoc/FishBAIT is an application/software that aims to fill this gap, by a quick examination against a databank of pathogen’s protein structures. The application screens thousands of protein structures at a time against input molecules using the RASPD+ logic and provides information on potential protein targets for molecules under investigation. Ref.: Manuscript in preparation |
21. Sites of metabolism (SOM) : Knowledge of sites of metabolism (SOM) of a molecule and its biotransformation products can help not only in optimizing the lead molecule with favourable metabolic profile but also in reducing toxicity and enhancing bioavailability and bioactivity. Ref.: G. Mukherjee, P. L. Gupta, B. Jayaram, "Predicting the binding modes and sites of metabolism of xenobiotics", *Molecular BioSystems*, 2015, 11, 1914 - 1924. DOI:10.1039/C5MB00118H |
22. Intercalate: Intercalate is a web server, dedicated for DNA intercalation process, which predicts the structure and energetics of DNA-intercalator complexes. It also incorporates an algorithm for creating the DNA structure having the intercalation site from the given nucleotide sequence and intercalation site information. Followed by, it performs Monte Carlo docking and scoring for the prediction of ligand binding modes and binding free energy estimations. Ref.: Anjali Soni, Pooja Khurana, Tanya Singh, B. Jayaram, "A DNA Intercalation Methodology for an Efficient Prediction of Ligand Binding Pose and Energetics",Bioinformatics, 2017. https://doi.org/10.1093/bioinformatics/btx006 |
23. Multi Target Ligand Design (MTLD): Multi Target Ligand Design (MTLD) is a web server that helps to identify common leads for any two protein targets. The basic principle of identifying common small molecules inhibiting multiple targets, remains the active site similarity and common interactive residues in their binding pockets. The protocol is based on the utilization of already established and validated softwares which are harnessed here to provide a set of common ligands for multiple proteins. Ref.: Jayaraj A., Bhat R., Pathak A., Singh M., Jayaram B. "Development of a Web-Server for Identification of Common Lead Molecules for Multiple Protein Targets". In: Methods in Pharmacology and Toxicology. Humana Press, 2018: 1-18. DOI: 10.1007/7653_2018_9. |
24. Sanjevini Android application: Sanjeevini application for smart phones for Computer Aided Drug Design (CADD) |